U.S. Presidential pardon power….
Out with the old and in with the new. Not before the age old tradition of U.S. presidential pardons (or “Executive Clemency”). Similar to previous presidents, Trump primarily leveraged this immediately prior to his departure. Dissimilar to his predecessors, the level and magnitude of the original charges being pardoned.
For brevity, I have pulled down the list from Wikipedia, which assuredly introduces some bias. The full official list from the U.S. Department of Justice can be found here.
if(!require(pacman)){
install.packages("pacman")
library(pacman)
}
p_load(tidyverse, tidytext, textdata, textclean,
htmlwidgets, webshot,
fs, tools, rvest, lubridate, janitor, purrr, wordcloud2)
# devtools::install_github("ropensci/genderdata")
# Additional pacakages, not used: gender, genderdata, devtools
# Extract States from Sentencing Court
state_pattern_detect <- paste0(paste0(".*\\b(", paste0(state.name, collapse="|"),
" |District of Columbia"), ")\\b.*")
# Sentiment to determine what types of sentiment is within the notes about
# the pardon
nrc_sentiment <- get_sentiments("nrc")%>%
group_by(word)%>%
mutate(all_sentiment = paste0(sentiment, collapse = " | "))%>%
filter(row_number() == 1)%>%
ungroup()Read-in data and perform some basic cleaning
- Read data with rvest package
- Clean dates, extract jurisdiction state
- Clean up text by removing certain terms, stopwords, numbers, etc.
- Use tidytext to create term frequency data frame
- bonus: for fun we add some sentiment data
# Link to wiki on the topic
pardon_url <- "https://en.wikipedia.org/wiki/List_of_people_granted_executive_clemency_by_Donald_Trump"
#xpath of table
tbl_xpath <- "//*[@id='mw-content-text']/div[1]/table[2]"
# Read in data and make adjustment to column header names
# Extract state jurisdictions, adjust dates
# **Primary Bonus Chart Dataset**
d_in_tbl <- read_html(pardon_url)%>%
html_node(xpath = tbl_xpath)%>%
html_table(., header = T, trim = T, fill = T)%>%
clean_names(.)%>%
set_names(., ~str_sub(., 0, nchar(.)-3))%>%
mutate(date_of_pardon = as.Date(date_of_pardon, format = "%B %d, %Y")%>%
ymd(.),
state_full = gsub(state_pattern_detect, "\\1", court),
first_name = gsub( " .*$", "",name))%>%
separate(date_of_pardon, sep="-",
into=c(sprintf("date_%s", c("yr", "mo", "day"))),
remove = F)%>%
rename(note = no)
# Create text file by uniting relevant columns
d_text_full <- d_in_tbl%>%
select(name, offense, note)%>%
unite("text", c("offense", "note"), sep = " ")%>%
mutate(text = textclean::replace_names(text, replacement = ""),
name_id = row_number())%>%
mutate(text = str_replace_all(text, pattern = "[0-9]", " "))
# Get word counts **Primary WordCloud Plot Dataset**
d_word_freq_all <- d_text_full%>%
unnest_tokens(word, text)%>%
anti_join(stop_words)%>%
count(word, sort = T)%>%
inner_join(nrc_sentiment)%>%
filter(!word %in% c("trump", "pardon"))
d_word_freq_name <- d_text_full%>%
group_by(name)%>%
unnest_tokens(word, text)%>%
ungroup()%>%
anti_join(stop_words)%>%
count(word, name, sort = T)%>%
ungroup()%>%
filter(!word %in% c("trump", "pardon"))
d_sentiment <- d_text_full%>%
unnest_tokens(word, text)%>%
anti_join(stop_words)%>%
inner_join(nrc_sentiment)%>%
count(word,sentiment, sort = T)%>%
ungroup()
d_bing_sentiment <- d_text_full%>%
unnest_tokens(word, text)%>%
anti_join(stop_words)%>%
inner_join(get_sentiments("bing"))
d_bing_word_cnt <- d_text_full%>%
unnest_tokens(word, text)%>%
anti_join(stop_words)%>%
inner_join(get_sentiments("bing"))%>%
count(word, sentiment, sort = T)%>%
ungroup()Wordcloud for all text associated with Trump pardons, where the word occurs more than 4 times
p_wc <- d_word_freq_all%>%
filter(n > 4)%>%
wordcloud2(., shape = "pentagon", size = 1,
maxRotation = -pi/6, rotateRatio = .2,
color = "random-light", backgroundColor = "black")
p_wc# Function to generate plot locally
# Code sourced from here w/ minor adjustments: http://rstudio-pubs-static.s3.amazonaws.com/564823_960901304f4e4853ba7dbc93eb4bc499.html
# f_wc_widget <- function(widget,path=getwd(),filename="file.png"){
# require(htmlwidgets)
# require(webshot)
# saveWidget(widget,"tmp.html",selfcontained = F)
# file <- paste(path,filename,sep = "/")
# webshot("tmp.html",file,delay = 10,vwidth = 1024,vheight = 768)
# file.remove("tmp.html")
# paste0("\n\n") %>% cat()
# }
#
# f_wc_widget(p_wc, filename = "trumpPardon.png")Bonus Plots
- Pardons by term year
- Pardons by original prosecuting jurisdiction
- Top terms usage broken down by positive and negative sentiment
p1 <- d_in_tbl%>%
mutate(term_year = case_when(
date_of_pardon < ymd("2018-01-21") ~ "1. First Year of Term",
date_of_pardon > ymd("2018-01-21") &
date_of_pardon < ymd("2019-01-21") ~ "2. Second Year of Term",
date_of_pardon > ymd("2019-01-21") &
date_of_pardon < ymd("2020-01-21") ~ "3. Third Year of Term",
TRUE ~ "4. Final Term"))%>%
group_by(term_year)%>%
summarize(cnt = n())%>%
ggplot()+
geom_bar(stat = "identity", aes(x = term_year, y = cnt))+
coord_flip()+
labs(x = "Term",
y = "# Pardons")+
theme_minimal()
# Pardons by Jurisdiction
p2 <- d_in_tbl%>%
group_by(state_full)%>%
summarize(cnt = n())%>%
ggplot()+
geom_bar(stat = "identity", aes(x = reorder(state_full,cnt), y = cnt))+
coord_flip()+
labs(x = "Orig. sentencing \n jurisdiction",
y = "# of Pardons")+
theme_minimal()
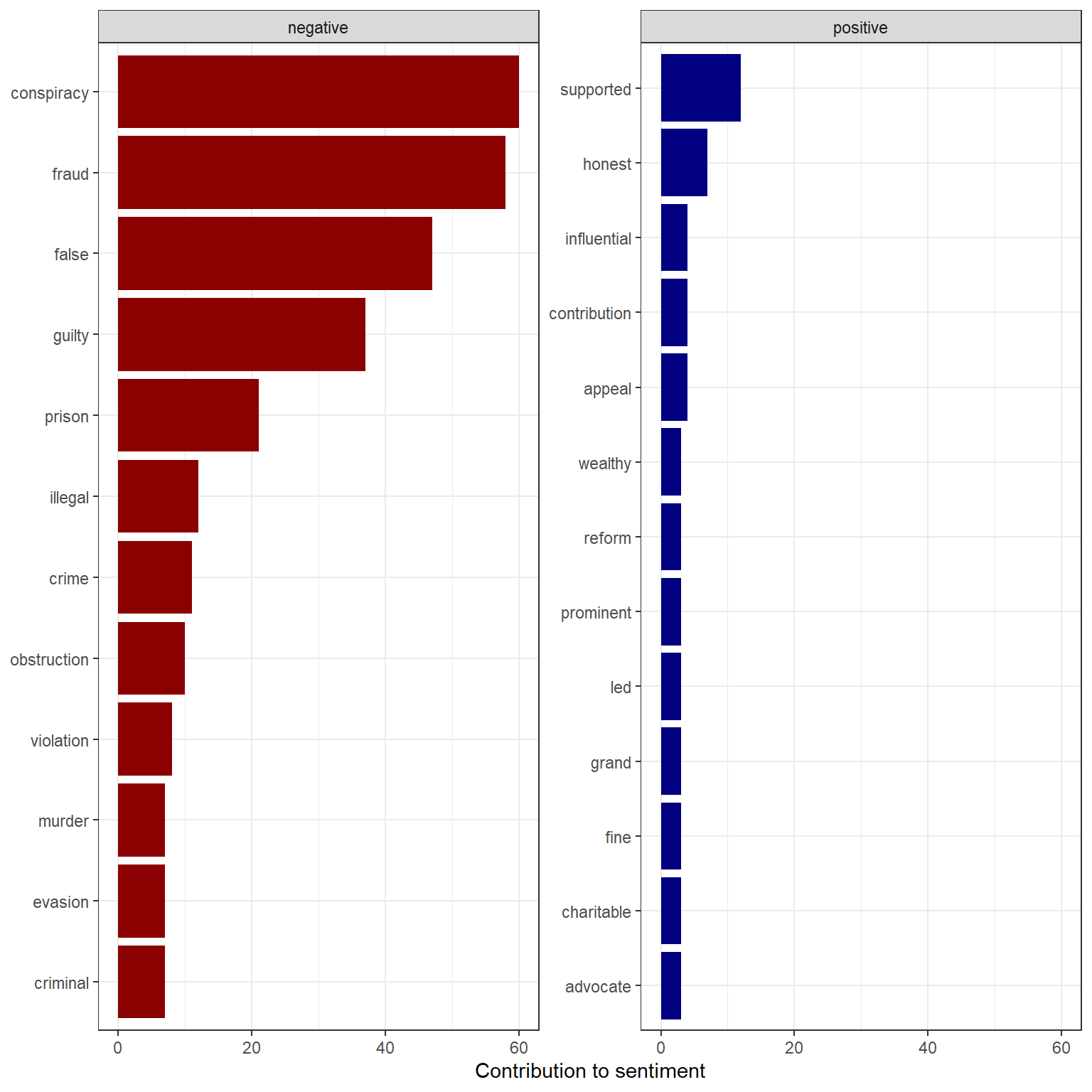
# Sentiment of top 10 positive and negative terms by term frequency
p3 <- d_bing_word_cnt%>%
group_by(sentiment)%>%
top_n(10)%>%
ungroup()%>%
mutate(word = reorder(word, n))%>%
filter(!word %in% c("trump", "pardon"))%>%
ggplot(aes(n, word, fill = sentiment))+
scale_fill_manual(values = c("darkred", "navy"))+
geom_col(show.legend = F)+
facet_wrap(~sentiment, scales = "free_y")+
labs( x= "Contribution to sentiment",
y = NULL)+
theme_bw()
p1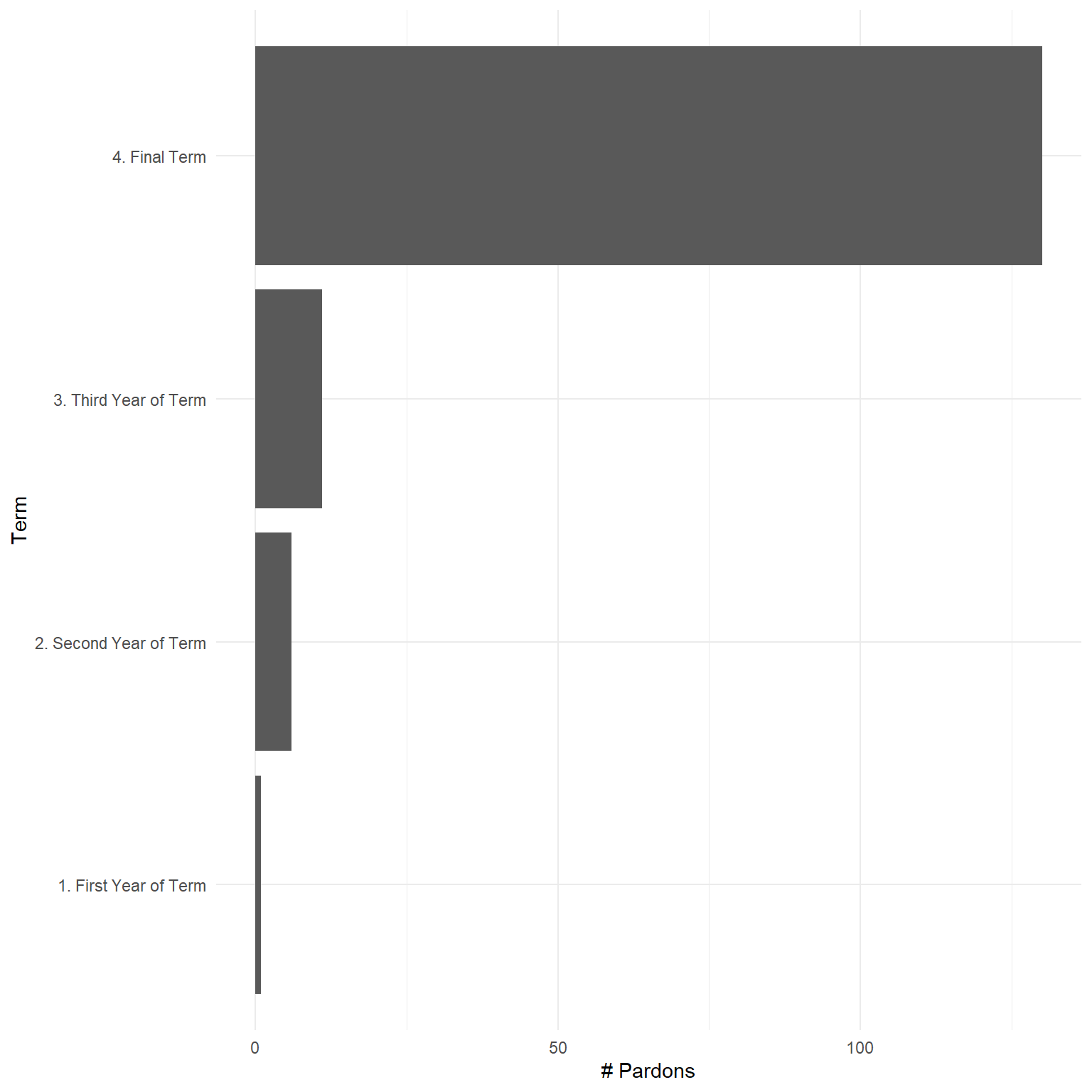
p2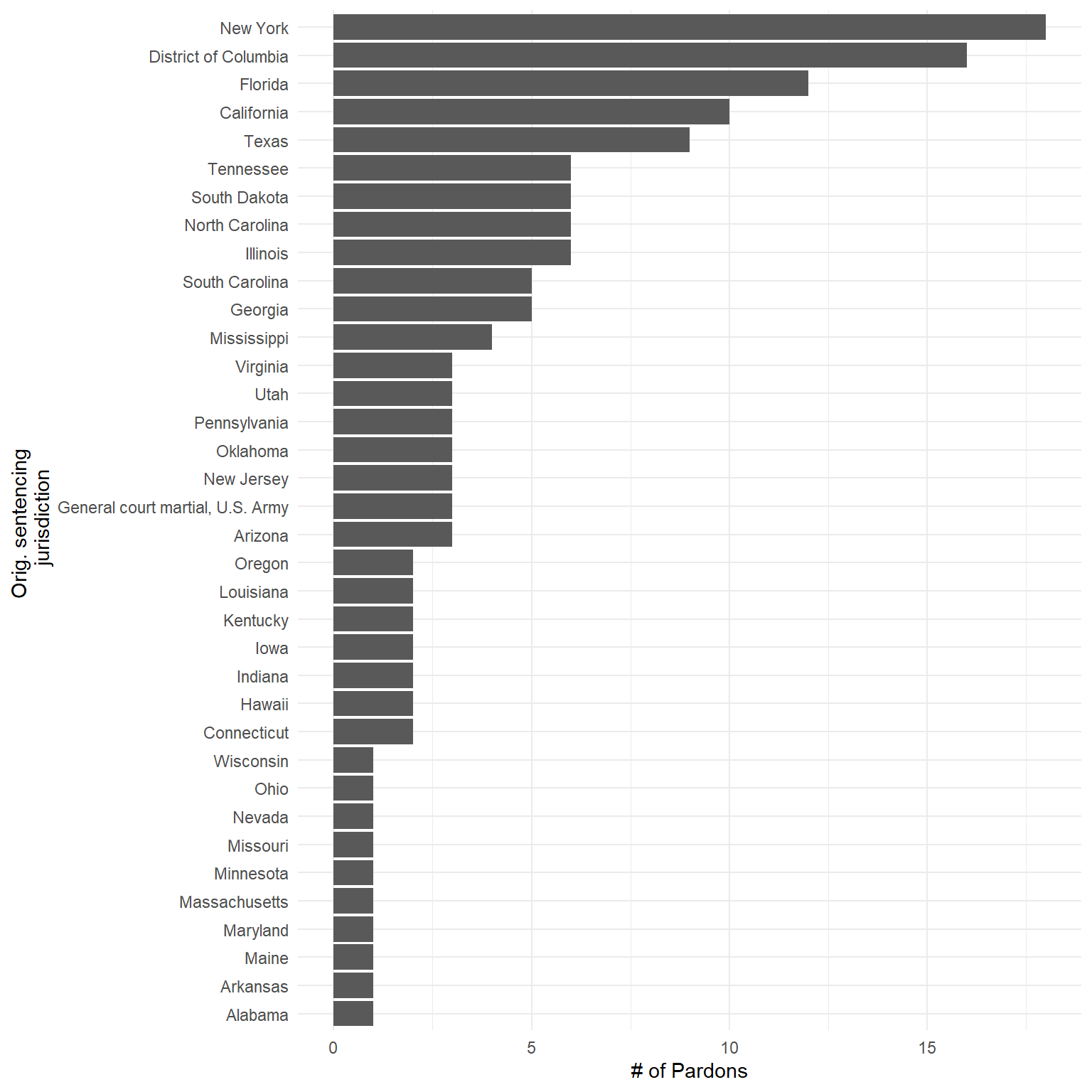
p3